Single Source Development with Castor and XDoclet
Notes and Examples
Abstract:
|
Castor
provides XML data binding and O/R mapping in a very usable package.
In new application development Castor, along with Ant and XDoclet,
can effectively lower the cost of prototyping and shorten the
distance from prototype to release. |
Castor is an open source data binding tool kit created at exolab.org. Since its introduction in 2000 Castor has been involved in a number of projects and has been included as a component in several commercial products. It is considered generally well built and stable. The four main parts of Castor are:
- XML
Java → XML binding - JDO
Object relational mapping
Note: Castor's JDO does not follow Sun's JDO spec. - DAX
Object LDAP mapping - DSML
Object → XML → LDAP mapping
O/R mapping is a part of most business applications. The tools are relatively similar and generally involve creating declarative mapping files. In a perfect world a perfect O/R mapping tool would do a lot to speed development. In reality O/R mapping is a relative pain in the neck compared to using the data once it has been mapped to objects.
Without attempting to break any new ground, this article shows how it is possible to create an object model from an XML schema, and include mapping instructions in that schema that can be interpreted by XDoclet to generate the mapping file. An outline of the process is shown in Figure 1, below. XDoclet is a tool that interprets Javadoc tags to generate supporting files (Home beans, descriptors, etc). The usual way to run XDoclet is as a task in everyone's favorite build tool: Ant.
From there it will be a fairly straightforward exercise for the reader to have XDoclet also generate other supporting code. For example a set of JSP pages to test the model or a layer of stateless session beans (with their interfaces and descriptors) to proxy for the dominant JavaBeans. All sorts of clever extensions are possible. The only goal here is simply to outline one reasonable, low friction development model (with a flavor of Continuous Integration and Model Driven Architecture). This article offers a particular method and a place to begin exploring how far a 'single source' approach for database Java applications can go.
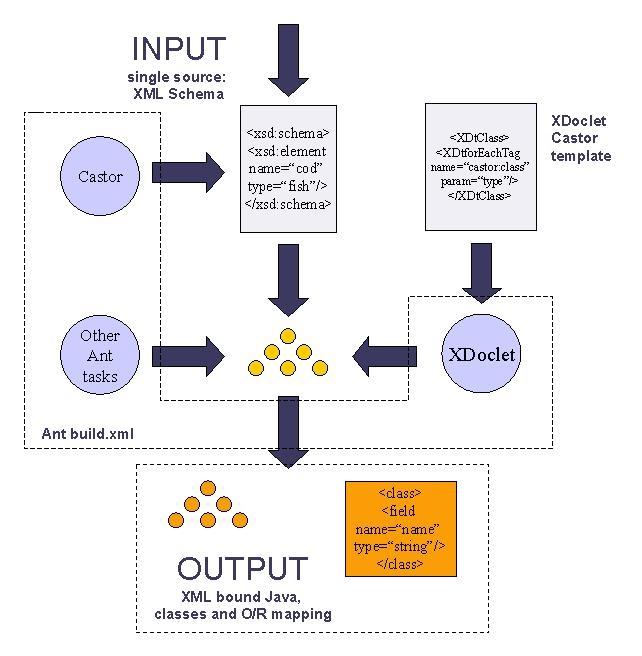
|
| Figure 1. Overview of the process: XSD to mapped Java classes |
We are going to build a simple data oriented application prototype: a catalog and shopping cart. It won't be a complete application but it will give a good example and a place to start. The steps we are going to walk through are:
- Create the application's abstract schema as an XSD
- Generate castor classes from the abstract schema
- Compile the castor classes
- Generate a castor O/R mapping file using xDoclet
- Create castor database descriptor
There are also several preparatory steps that must be taken before trying this approach with any application. These steps include:
- Setup the Castor template in XDoclet
- A simple modification to the Castor framework to improve mapping support
- Prepare the Ant script that drives the process
PREPARATION
XDoclet behavior is driven by an Ant task (in our case, since we are using Ant). Each task may have subtasks. We will leverage the existing EjbDocletTask and add the existing CastorSubTask to drive the mapping file generation. The EjbDocletTask is geared towards generating all the files needed to deploy EJBs. Since we can use it to do as much or as little as needed this is a fine platform, even though we are not going to create EJBs. In the same way, the Castor subtask is aimed at generating data objects to support BMP entity beans. Because this is not what we are after we'll need to make some changes. Luckily the changes are all confined to the runtime interpreted template file mapping-body.j.
Skipping ahead a bit, one thing to realize is that we are limited with respect to XDoclet by the source code generator in Castor. Unless someone can explain different (or cares to modify the source), Castor's SourceGenerator application (org.exolab.castor.builder.SourceGenerator) will not apply <documentation> tags to members as source comments. It will, however, apply documentation at the class level. Since we can put Javadoc tags at the class level but not at the field or method level we have to set all the needed info into one chunk of documentation (see: commerce.xsd). This is actually a good thing (once you think it though) since it keeps all the metadata for a class in one place.
Still, the original 'mapping-body.j' template was written to handle regular Javadoc tags at the class and member levels, so we have some changes to make. Quick caveat, the following approach to XDoclet's templates is not necessarily the best, but it is entirely workable and seems straightforward--the XDoclet wizards out there should send your tips! The template code below iterates through the class level tags per Java file and structures a set of XML elements defining the mapping. The output, tags used and a quick explanation are given below.
|
<XDtClass:forAllClassTags tagName="castor:class">
|
The modified mapping-body.j can replace the original in the xdoclet jar file. There shouldn't be any material effect on the designed use of the file with this addition.
The tags this modification looks for are under the namespace 'castor' and the tag name 'class'. Functional use can be seen in the example schema. Please also consult the XDoclet tags documentation for the existing Castor tags (mostly defaulted in this example). The most important tags (mainly new or modified) are:
- id
The identity field of the relational entity underlying the generated class - table
The table of entity - depends
If this is a dependent object (e.g. a catalog item depends on a catalog) the fully qualified class name of the superior object goes here - field-name
A field name is a Schema element identifier. Within the mapping file this will structure references to SQL, Java and XML names - field-type
The type is 'string', 'integer', etc. See the Castor documentation for the complete list. - sql-name
The field name within a relational table that maps to this property - sql-type
A SQL type - method-name
A field's Java name. Is used to map accessors and mutators so use appropriate casing.
Now we get to the issue of what preparation we need to do to Castor itself. The need is for a couple of simple changes to the code generation application to make it better support 'single source' development. Since Castor includes a general source code generation framework as a separate package, changing the way Castor's code generation application generates code is relatively easy. Although the modifications are small I'm not pleased to be making them ad hoc. If someone knows of a work around (or a more correct usage) I'd like to see it; however, after trying several things and prowling around in the source for a while I'm thinking this is the best answer.
The problem is as follows. Castor permits mapping existing JavaBeans or generating new beans from XSD. There is collections support for existing beans that have one-many or many-many relationships. That support extends to generated beans with one exception: the batch accessor/mutator methods involved in 'many' operations are generated to get and set arrays of the dependant type. Internally the dependent objects are held in collections. The O/R framework does not support arrays (though conceivably it could), and although the collection attribute can be set to 'array' or 'vector' (see the Castor documentation on the proper use) the capabilities of the generator and the mapping framework don't match up.
One solution would be to simply modify the affected property methods to set/get List or Vector. But that would keep us from the goal of getting closer to a lights-out single source application. The change needed to make Castor generate the correct signatures is not a big deal. One class is affected: org.exolab.castor.builder.CollectionInfo. The changes are shown in the figures below.
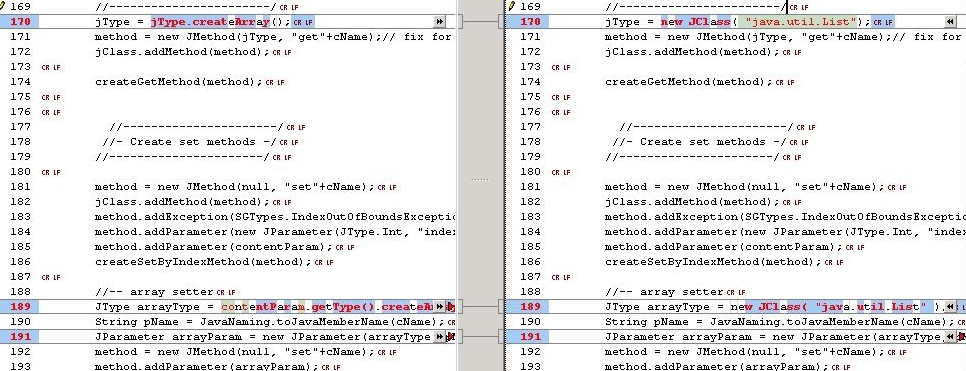
|
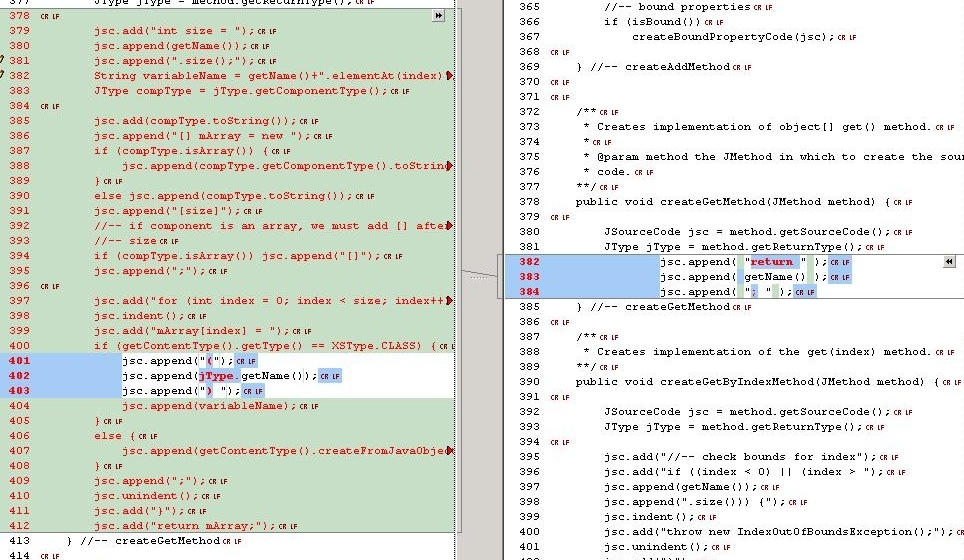
|
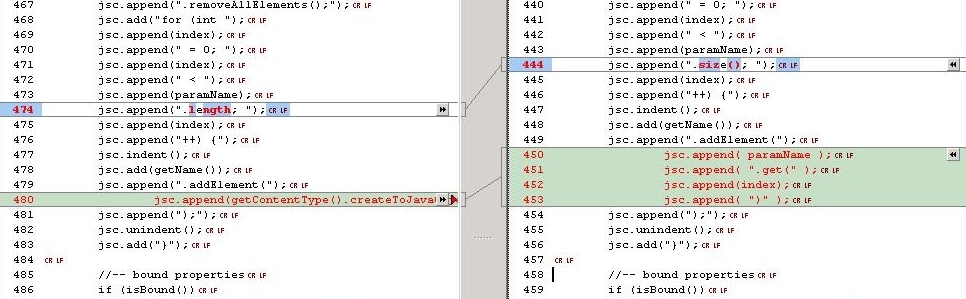
|
| Figure 2, 3, 4. Modifying Castor: before and after. |
Rather than add this only lightly tested change to Castor, just compile the class and put it ahead of castor.jar in your classpath. With this change made we should be ready to move on to application specific development.
DEVELOPMENT STEPS
The first development step is to model our system in abstract form as a W3C schema. From this abstract model we will use tools to generate Java source, O/R mappings, and compiled classes. As stated above, the goal is development efficiency. In this context, efficiency can be thought of several ways: speed of development, few bugs, quick modification, etc. Our focus is on:
- Clear representation of domain knowledge
- Highly automated builds
- Easy customization.
The commerce.xsd file contains a rudimentary schema describing a cart/catalog component. Remember this is not an attempt to describe a production system; however, at the end of this example it should be clear how this simple prototype can evolve. Conceptually, the structure in commerce.xsd is something like that shown in figure 5, below.
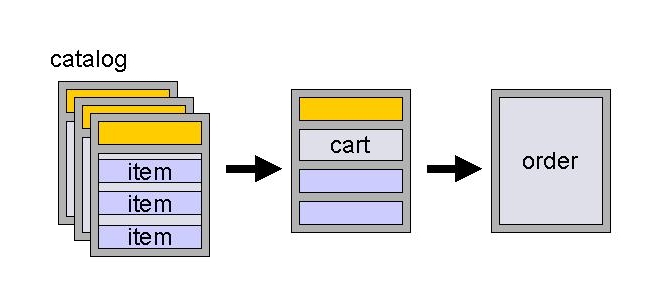
|
| Figure 5. A conceptual depiction of the commerce component. |
Each global element in the schema has an annotation element containing documentation. These documentation sections must serve two goals: document the implementation and provide XDoclet instructions as Javadoc tags. The downside is that the documentation is dense and may be cluttered. But with all (or the majority) of the configuration information in one relevant place with the text describing the concept implementation we would be silly to complain too much. The working format for the Javadoc attributes is as follows.
|
<xsd:documentation>
@castor:class field-name="name" field-type="string" sql-name="NAME" sql-type="char" method-name="Name"
@castor:class field-name="img" field-type="string" sql-name="IMG" sql-type="char" method-name="Img"
|
How far this approach can go before our single source file is unreadably dense with metadata is anyone's guess. I found it necessary to hide annotations when using XML Spy's schema design view (see Figure 6, below), but that didn't inhibit me from understanding and working with the model. The approach may become a bit top heavy in a large component or multiple components, but problem domains can be effectively distributed across multiple schemas to improve modularity and understandability. Probably the biggest issue would be if more and more XDoclet instructions are added to drive new code generation tasks.
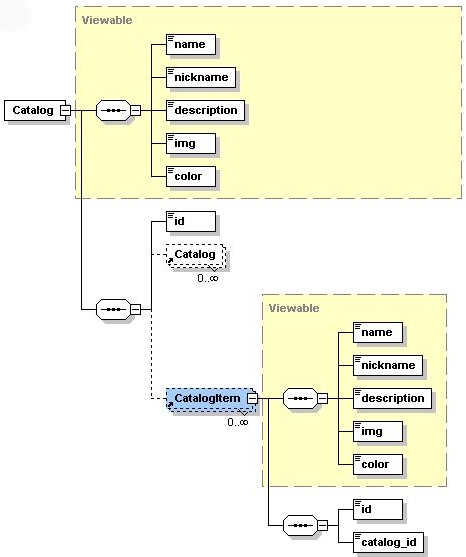
|
| Figure 6. A model view of the commerce schema. |
By now the reader is familiar with the project's Ant file. Ant will be used to run tasks for code generation, mapping file generation, and compilation. The first step is code generation. Castor's basic code generation concepts should be comfortable after the discussion above. The default interface to the com.exolab.castor.builder application is the SourceGen script that comes in the Castor distribution. However creating a simple Ant task (see the 'source' target) to drive the source generation is trivial. (Probably there is one already out there, but I have yet to see it). Second, we need to drive XDoclet to interpret the JavaDoc tags from our schema and now found in our Java code. Again, the set up is straightforward and the example build.xml gives you what you need to know under the 'castor' target. Finally, we need to apply the most basic of Ant duties, a compilation target. The minor effort of setting up the compile task is left as an exercise for the reader. Once that last step is accomplished you should be ready to take your schema to a compiled, XML bound, data mapped object model in one easy command line step.
SUMMARY
We have looked at a fairly simple first take on single source development based on XML schema, Castor, and XDoclet. Given solid platform tools, open access to tweak code, and some modest effort at build configuration we get a very easy to create, easy to modify core component for a realistic system. Furthermore, we not only just took the learning curve down a notch, but should see continuing improvement in productivity with each use. With the effort saved it is easy to imagine making incremental improvements to current functions and taking the approach in new directions.
I look forward to hearing about your successful developments and refinements on the model!